上传资源得积分
上传资源得积分 :sj52abcd
:sj52abcd
研究目的:
本研究旨在设计和实现一个基于Python的机器学习二手车价格分析预测系统。通过收集和分析二手车市场的相关数据,利用机器学习算法建立预测模型,为用户提供准确的二手车价格预测信息。具体目的包括以下几点:
1. 构建基于Python的系统框架,包括数据采集、数据预处理、特征选择、模型训练和预测等功能。
2. 收集并整理大量的二手车市场数据,包括车型、车龄、里程、品牌等特征,以及对应的价格信息。
3. 利用机器学习算法对数据进行分析和挖掘,建立准确的二手车价格预测模型。
4. 实现用户友好的界面,用户可以根据自身需求输入相关的二手车参数,系统将给出相应的价格预测结果。
开发背景:
随着经济的发展和人们生活水平的提高,越来越多的人开始购买二手车。然而,对于二手车的价格,很多人并不了解或者存在较大的不确定性。在购买或者销售二手车的过程中,准确的价格信息对于用户非常重要。因此,开发一个基于机器学习的二手车价格分析预测系统能够有效地解决这一问题,并为用户提供决策参考。
国外研究现状分析:
在国外,已有一些研究团队对二手车价格进行了相关研究。例如,某研究团队使用了支持向量机(Support Vector Machine, SVM)算法对二手车市场数据进行建模和预测,取得了较好的效果。另外,还有一些研究采用了随机森林(Random Forest)和神经网络(Neural Network)等机器学习算法,并通过对特征的挖掘和分析来提高预测的准确性。综合这些研究可以得出结论,机器学习算法在二手车价格预测方面具有潜力,并且可以达到一定的准确性。
国内研究现状分析:
国内对于二手车价格预测的研究相对较少,但也有一些相关研究可供参考。例如,某些研究采用了回归分析模型,利用车型、车龄、里程等特征对二手车价格进行预测,并取得了一定的成果。此外,还有研究团队利用遗传算法和模糊逻辑等方法来建立预测模型,提高预测的准确性。总体而言,国内的研究相对较少,还有很大的发展空间。
需求分析:
人用户需求:
- 用户需要一个能够准确预测二手车价格的系统,以便在购买或者销售二手车时做出明智的决策。
- 用户希望系统能够提供友好的界面,方便操作和使用。
- 用户需要系统能够及时更新二手车市场的数据,以保证预测的准确性。
功能需求:
- 数据采集:系统能够自动从各个渠道收集二手车市场的相关数据,并进行整理和存储。
- 数据预处理:系统能够对采集到的数据进行清洗、去重、缺失值处理等预处理操作
- 特征选择:系统能够通过特征选择算法,从众多的特征中选择出对二手车价格预测有最大影响的特征进行分析和建模。
- 模型训练:系统能够利用机器学习算法对选定的特征进行训练,建立准确的二手车价格预测模型。
- 预测功能:系统能够根据用户输入的二手车参数,对其价格进行预测,并显示预测结果。
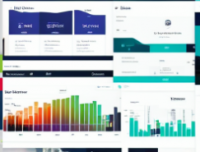
- 用户界面:系统提供用户友好的界面,用户可以方便地输入二手车的相关信息并获取预测结果。
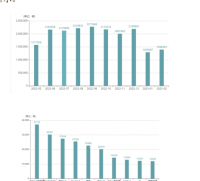
- 数据可视化:系统能够将数据和模型的分析结果以可视化的方式展示,例如图表、图形等形式,以便用户更好地理解和分析预测结果。
可行性分析:
经济可行性:
- 二手车市场具有巨大的潜力和需求,开发和运营这样一个系统具有经济可行性。可以通过广告投放、收取使用费用等方式获取收入。
- 研究和开发相对于其他行业来说成本较低,且能够长期使用和维护。
社会可行性:
- 二手车价格分析预测系统能够提供准确的二手车价格信息,帮助用户做出更明智的决策,提高交易效率,有助于促进二手车市场的发展。
- 通过提供准确的价格预测,可以减少不透明的信息和价格不合理带来的纠纷,提高市场的透明度和公平性。
技术可行性:
- Python作为一种流行的编程语言,在机器学习领域有着丰富的库和工具支持,能够方便地进行数据处理、模型训练等操作。
- 机器学习算法的应用已经得到广泛的验证和应用,能够提供相对准确的预测结果。
功能分析:
基于需求分析,本系统的主要功能包括:
1. 数据采集模块:负责从各个数据源收集二手车市场的相关数据,并进行整理和存储。
2. 数据预处理模块:对采集到的数据进行清洗、去重、缺失值处理等预处理操作,以准备后续的分析和建模。
3. 特征选择模块:使用特征选择算法,从众多的特征中选择出对二手车价格预测有最大影响的特征。
4. 模型训练模块:利用机器学习算法对选定的特征进行训练,建立准确的二手车价格预测模型。
5. 预测模块:根据用户输入的二手车参数,调用训练好的模型进行价格预测,并返回预测结果。
6. 用户界面模块:提供用户友好的界面,用户可以方便地输入二手车的相关信息并获取预测结果。
7. 数据可视化模块:将数据和模型的分析结果以可视化的方式展示,例如图表、图形等形式,以便用户更好地理解和分析预测结果。
使用Python实现二手车价格的预测:
```python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 读取数据集
data = pd.read_csv('used_car_data.csv')
# 数据预处理
# ...
# 特征选择
# ...
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 模型训练
model.fit(X_train, y_train)
# 预测
new_car = {'car_age': 3, 'mileage': 50000, 'brand': 'BMW', 'model': 'X5'}
new_car_df = pd.DataFrame([new_car])
new_car_features = preprocess_features(new_car_df) # 预处理新车特征
prediction = model.predict(new_car_features)
print(f'预测的二手车价格为: {prediction[0]:.2f}万元')
```
步骤包括:
1. 导入所需的库。
2. 读取二手车数据集。
3. 进行数据预处理,比如清洗数据、处理缺失值等。
4. 进行特征选择,选择对价格预测有最大影响的特征。
5. 划分数据集为训练集和测试集。
6. 创建线性回归模型。
7. 对模型进行训练,使用训练集的特征和标签。
8. 使用预训练好的模型进行二手车价格预测,输入新车特征并获取预测结果。
9. 打印预测结果。