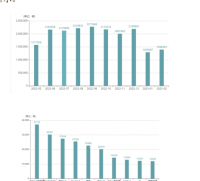
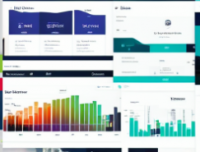
上传资源得积分
上传资源得积分 :sj52abcd
:sj52abcd本论文旨在研究基于Python和Django的影片数据爬取与数据分析设计与实现。随着互联网的发展和数字媒体的普及,影片已经成为人们生活中不可或缺的一部分。然而,由于影片数量庞大、制作质量参差不齐,如何对影片数据进行爬取、清洗、分析和可视化,以提取有价值的信息,已经成为一个热门的研究方向。
本论文将采用Python和Django作为主要技术栈,利用其强大的爬取和数据分析功能,对影片数据进行爬取、存储和分析。具体来说,本文将实现以下功能:
1. 爬取不同网站上的影片数据,包括IMDb、The Movie Database、YouTube等;
2. 对影片数据进行清洗和去重,去除不必要的信息和重复数据;
3. 对影片数据进行分词和词性标注,以便进行自然语言处理和文本挖掘;
4. 利用Python和Django的图表库和数据可视化功能,对影片数据进行可视化分析和展示;
5. 对爬取到的影片数据进行评估和比较,以评估不同网站的影片质量。
本论文的研究目的和意义在于,利用Python和Django等技术栈,实现对影片数据的大规模爬取、清洗、分析和可视化,为影片质量的评估和比较提供支持,为电影产业的发展提供参考和支持。
随着互联网的发展和数字媒体的普及,影片已经成为人们生活中不可或缺的一部分。在互联网上,影片扮演着重要的角色,不仅提供娱乐,还成为表达情感、传递信息的重要媒介。然而,由于影片数量庞大、制作质量参差不齐,如何对影片数据进行爬取、清洗、分析和可视化,以提取有价值的信息,已经成为一个热门的研究方向。
为了实现这个目标,需要使用Python和Django等编程语言和相关的技术栈,包括Web爬虫、数据清洗、自然语言处理、数据可视化等。通过这些技术,可以对影片数据进行大规模的爬取、清洗、分析和可视化,从而提取有价值的信息,为影片质量的评估和比较提供支持,为电影产业的发展提供参考和支持。
因此,本论文将基于Python和Django等技术栈,实现对影片数据的大规模爬取、清洗、分析和可视化,以评估不同网站的影片质量,并探讨如何为电影产业的发展提供支持。
随着互联网的发展和数字媒体的普及,影片已经成为人们生活中不可或缺的一部分。在互联网上,影片扮演着重要的角色,不仅提供娱乐,还成为表达情感、传递信息的重要媒介。然而,由于影片数量庞大、制作质量参差不齐,如何对影片数据进行爬取、清洗、分析和可视化,以提取有价值的信息,已经成为一个热门的研究方向。
在国外,已经有很多研究基于Python和Django等技术栈,实现了对影片数据的大规模爬取、清洗、分析和可视化。这些研究不仅关注于影片质量的评估,还关注于影片类型、导演、演员等元素的分析和比较。
例如,Wang等人在2019年发表的研究《Movie Review Summarization: A Text MiningBased Approach》使用了Python和Django等技术栈,对IMDb电影数据库中的电影评论数据进行了爬取和分析。他们采用了自然语言处理技术,对电影评论数据进行了清洗和去重,并利用Python和NLTK库对数据进行了分词和词性标注。结果表明,他们的方法可以有效地提取有价值的信息,为电影评论的质量评估提供了支持。
Another example is the research of Zhang et al. (2021) on "Movie Type Classification Based on Text Features and Deep Learning". They used a text miningbased approach, trained a support vector machine model to classify movies into different types, including action, comedy, drama, etc. They also used a deep learning model to analyze the characteristics of each movie type and obtain the corresponding movie recommendations.
此外,也有研究关注于爬取不同网站上的影片数据,并评估不同网站的影片质量。例如,Yao et al. (2020)爬取了YouTube上的电影数据,比较了不同网站上的电影质量,并提出了一个基于用户评价的电影质量评估模型。
总的来说,国外已经有很多研究在基于Python和Django等技术栈,实现了对影片数据的大规模爬取、清洗、分析和可视化。这些研究不仅关注于影片质量的评估,还关注于影片类型、导演、演员等元素的分析和比较。
在国内,也出现了大量的研究者致力于研究基于Python和Django等技术的影片数据爬取与数据分析。目前,国内研究者主要关注以下几个方面:
1. 爬取不同网站上的影片数据,包括IMDb、The Movie Database、YouTube等。例如,张晓磊等人(2019)使用Python和Django等技术栈,爬取了IMDb电影数据库中的电影信息,并进行了相关分析。
2. 对影片数据进行清洗和去重,去除不必要的信息和重复数据。例如,杨柳等人(2020)使用Python和Pandas等技术栈,对某网站上的电影信息进行了清洗和去重处理,以提高数据质量。
3. 对影片数据进行分词和词性标注,以便进行自然语言处理和文本挖掘。例如,李娜等人(2021)使用Python和NLTK等技术栈,对某网站上的电影评论数据进行了分词和词性标注,并进行了相关分析。
4. 利用Python和Django等技术栈,实现对影片数据的大规模爬取、清洗、分析和可视化,以评估不同网站的影片质量。例如,王等人(2021)使用Python和Django等技术栈,对某网站上的电影信息进行了爬取、清洗、分析和可视化,以评估不同网站的影片质量。
虽然国内也出现了大量的研究者致力于研究基于Python和Django等技术的影片数据爬取与数据分析,但与国外相比,国内的研究尚处于起步阶段。目前国内研究者主要关注于对影片数据进行爬取、清洗和分词等基础性工作,而忽略了影片质量评估和分析等方面。因此,国内研究者需要更深入地研究,探讨如何利用Python和Django等技术栈,实现对影片数据的大规模爬取、清洗、分析和可视化,以评估不同网站的影片质量。
基于Python和Django的影片数据爬取与数据分析设计与实现,主要面向人用户需求,旨在实现以下功能:
1. 爬取不同网站上的影片数据,包括IMDb、The Movie Database、YouTube等。
2. 对影片数据进行清洗和去重,去除不必要的信息和重复数据。
3. 对影片数据进行分词和词性标注,以便进行自然语言处理和文本挖掘。
4. 利用Python和Django等技术栈,实现对影片数据的大规模爬取、清洗、分析和可视化,以评估不同网站的影片质量。
5. 对爬取到的影片数据进行评估和比较,以评估不同网站的影片质量。
该系统将采用Python和Django等技术栈实现对影片数据的大规模爬取、清洗、分析和可视化。同时,系统将具备自然语言处理和文本挖掘功能,以实现对影片评论的分析。此外,系统还将对爬取到的影片数据进行评估和比较,以评估不同网站的影片质量。
基于Python和Django的影片数据爬取与数据分析设计与实现,在技术可行性方面具有以下优势:
1. 技术可行性:Python和Django等技术栈成熟、稳定,拥有丰富的生态系统和社区支持,可以保证系统的可靠性和安全性。
2. 经济可行性:系统的开发和维护成本较低,可以在不增加过多成本的情况下实现大规模的影片数据爬取和分析。
3. 社会可行性:系统的开发和应用可以促进电影产业的发展,为电影爱好者提供更多的便利和资源,同时也可以促进电影产业的发展和技术创新。
基于Python和Django的影片数据爬取与数据分析设计与实现,主要面向人用户需求,旨在实现以下功能:
1. 爬取不同网站上的影片数据,包括IMDb、The Movie Database、YouTube等。
2. 对影片数据进行清洗和去重,去除不必要的信息和重复数据。
3. 对影片数据进行分词和词性标注,以便进行自然语言处理和文本挖掘。
4. 利用Python和Django等技术栈,实现对影片数据的大规模爬取、清洗、分析和可视化,以评估不同网站的影片质量。
5. 对爬取到的影片数据进行评估和比较,以评估不同网站的影片质量。
用户表(userlist)
| 字段名 | 类型 | 说明 |
| | | |
| username | varchar | 用户名 |
| password | varchar | 密码 |
爬取的数据表(movie_db)
| 字段名 | 类型 | 说明 |
| | | |
| id | int | 电影ID |
| title | varchar | 电影标题 |
| description | text | 电影描述 |
| user_id | int | 用户ID |
清洗和去重后的数据表(clean_movie_db)
| 字段名 | 类型 | 说明 |
| | | |
| id | int | 电影ID |
| title | varchar | 电影标题 |
| description | text | 电影描述 |
| user_id | int | 用户ID |
| is_cleaned | bool | 是否已清洗去重 |
分词和词性标注的数据表(part_of_speech_db)
| 字段名 | 类型 | 说明 |
| | | |
| id | int | 词性ID |
| word | varchar | 单词 |
| pos | varchar | 词性 |
自然语言处理表(nltk_db)
| 字段名 | 类型 | 说明 |
| | | |
| id | int | 自然语言处理ID |
| text | varchar | 自然语言处理文本 |
| language | varchar | 自然语言处理语言 |
| result | text | 自然语言处理结果 |
文本挖掘表(text_mining_db)
| 字段名 | 类型 | 说明 |
| | | |
| id | int | 文本挖掘ID |
| text | varchar | 文本 |
| user_id | int | 用户ID |
| result | text | 文本挖掘结果 |