 上传资源得积分
上传资源得积分 :sj52abcd
:sj52abcd
基于物品的协同过滤算法是目前业界应用做多的算法,如:亚马逊、YouTube其推荐算法基础都是该算法。基于物品的协同过滤在解决物品数量一定,但用户数量巨大的应用场景上很有优势,与本次实验解决问题类型相近故选用(豆瓣网站的电影数量是一定的,但是用户数量巨大。)在本次实验中ItemCF算法的实现思想主要为以下两个步骤: 1.计算物品间的相似度: 从物品上出发,可以定义物品的相似度计算公式为:$$w_{i j}=frac{|N(i) cap N(j)|}{|N(i)|}$$ 其中分母|N(i)|是喜欢物品i的用户数,分子${|N(i) cap N(j)|}$是既喜欢物品i同时也喜欢物品j的用户数量。不难看出,公式的定义是喜欢物品i的用户同时也喜欢物品j的用户比例,该公式一定程度上可以反映物品i、j的相似程度,但是对于j是热门物品的情况,其很多人都喜欢j,j的体量本身就很大,那么上述公式的计算结果 将接近于1,这对对于致力于挖掘长尾信息的推荐来说显然是一个不好的特性。因此,在此基础上加入对物品j权重的惩罚,得到改进的相似度计算公式为: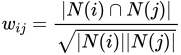 计算物品相似度的算法部分实现思路为: (1)建立用户-物品倒排表(对每个用户建立一个其喜欢的物品的列表); (2)对于每个用户,将其的物品列表两两在共现矩阵中加1; (3)将各用户的共现矩阵相加得到总的共现矩阵C; (4)将C矩阵归一化即得到物品之间的余弦相似矩阵W。 形象的实现思路如图: 2.根据物品相似度和用户的历史行为生成个性化的推荐列表: 在计算得到物品间的相似度后,再同如下公式计算得到用户u对物品j的兴趣:$$ p_{ ext {uj }}=sum_{i=N(u) cap s(j, K)} w_{j i} r_{u i} $$ 其中N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品集合,s(j,K)是与物品j最相似的K个物品的集合,wij是物品i与物品j的相似度,rui是用户u对物品j的兴趣。(在隐反馈数据集中,如果用户u对i有过行为,即可令rui=1),不难看出,该公式的含义为:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中排名越高。 生成个性化用户推荐列表的算法部分实现思想如下: (1)计算用户u对各个物品的兴趣得分; (2)按照用户u对各物品的兴趣得分按从大到小排序后生成推荐列表。 形象化的实现思
计算物品相似度的算法部分实现思路为: (1)建立用户-物品倒排表(对每个用户建立一个其喜欢的物品的列表); (2)对于每个用户,将其的物品列表两两在共现矩阵中加1; (3)将各用户的共现矩阵相加得到总的共现矩阵C; (4)将C矩阵归一化即得到物品之间的余弦相似矩阵W。 形象的实现思路如图: 2.根据物品相似度和用户的历史行为生成个性化的推荐列表: 在计算得到物品间的相似度后,再同如下公式计算得到用户u对物品j的兴趣:$$ p_{ ext {uj }}=sum_{i=N(u) cap s(j, K)} w_{j i} r_{u i} $$ 其中N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品集合,s(j,K)是与物品j最相似的K个物品的集合,wij是物品i与物品j的相似度,rui是用户u对物品j的兴趣。(在隐反馈数据集中,如果用户u对i有过行为,即可令rui=1),不难看出,该公式的含义为:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中排名越高。 生成个性化用户推荐列表的算法部分实现思想如下: (1)计算用户u对各个物品的兴趣得分; (2)按照用户u对各物品的兴趣得分按从大到小排序后生成推荐列表。 形象化的实现思
python实现:
import pandas as pd
import numpy as np
import random
from sklearn.metrics.pairwise import cosine_similarity # 计算余弦相似度
# 用户ID映射
usersMap = dict(enumerate(list(user_df['user_id'].unique()))) # 电影id与其对应索引的映射关系
usersMap = dict(zip(usersMap.values(), usersMap.keys())) # 键值互换
# 电影ID映射
moviesMap_raw = dict(enumerate(list(movies_df['dataID']))) # 电影id与其对应索引的映射关系
moviesMap = dict(zip(moviesMap_raw.values(), moviesMap_raw.keys())) # 键值互换
n_users = user_df.user_id.unique().shape[0] # 用户总数
n_movies = movies_df.Movie_ID.unique().shape[0] # 电影总数
data_matrix = np.zeros((n_users, n_movies)) # 用户-物品矩阵雏形
# 构造用户-物品矩阵
for line in user_df.itertuples():
try:
data_matrix[usersMap[str(line[1])], moviesMap[line[2]]] = line[3]
except:
pass
# 电影余弦相似度矩阵
item_similarity = cosine_similarity(data_matrix.T) # 转置之后计算的才是电影的相似度
def rec_hot_movies():
'''
@功能: 获取热门推荐电影
@参数: 无
@返回: 热门推荐电影列表
'''
hot_movies = []
hot_movies_raw = movies_df[movies_df.date >= 2019]
hot_movies_raw = hot_movies_raw[hot_movies_raw.rate >= 8.7]
hot_movies_raw = hot_movies_raw.iloc[:,[1,2,3,4,5,6,7,9]]
for i in list(hot_movies_raw):
temp = []
for j in range(len(list(hot_movies_raw.name.unique()))):
temp.append(hot_movies_raw['{}'.format(i)].values.tolist()[j])
hot_movies.append(temp)
hot_rec_movies = [] # 存储热门推荐电影
for k in range(len(hot_movies[0])):
temp_rec_movies = []
for l in range(len(hot_movies)):
temp_rec_movies.append(hot_movies[l][k])
hot_rec_movies.append(temp_rec_movies)
return hot_rec_movies
def Recommend(movie_id, k): # movie_id:电影名关键词,k:为最相似的k部电影
'''
@功能: 获得推荐电影列表
@参数: 电影ID、每部电影选取最相似的数目
@返回: 推荐电影列表
'''
movie_list = [] # 存储结果
try:
# 过滤电影数据集,搜索找到对应的电影的id
movieid = list(movies_df[movies_df['dataID'] == movie_id].Movie_ID)[0]
# 获取该电影的余弦相似度数组
movie_similarity = item_similarity[movieid]
# 返回前k个最高相似度的索引位置
movie_similarity_index = np.argsort(-movie_similarity)[1:k+1] # argsort函数是将数组元素从小到大排列,返回对应的索引数组
for i in movie_similarity_index:
rec_movies = [] # 每部推荐的电影
rec_movies.append(list(movies_df[movies_df.Movie_ID == (i)].name)[0]) # 电影名
rec_movies.append(list(movies_df[movies_df.Movie_ID == (i)].actors)[0]) # 主演
if pd.isna(list(movies_df[movies_df.Movie_ID == (i)].style2)[0]) and pd.isna(list(movies_df[movies_df.Movie_ID == (i)].style3)[0]):
style = list(movies_df[movies_df.Movie_ID == (i)].style1)[0]
elif pd.isna(list(movies_df[movies_df.Movie_ID == (i)].style3)[0]):
style = list(movies_df[movies_df.Movie_ID == (i)].style1)[0] + ' ' + list(movies_df[movies_df.Movie_ID == (i)].style2)[0]
else:
style = list(movies_df[movies_df.Movie_ID == (i)].style1)[0] + ' ' + list(movies_df[movies_df.Movie_ID == (i)].style2)[0] + ' ' + list(movies_df[movies_df.Movie_ID == (i)].style3)[0]
rec_movies.append(style) # 电影类型
rec_movies.append(list(movies_df[movies_df.Movie_ID == (i)].rate)[0]) # 电影评分
rec_movies.append(list(movies_df[movies_df.Movie_ID == (i)].url)[0]) # 电影链接
movie_list.append(rec_movies) # 列表中的元素为列表,存储相关信息
except:
pass
return movie_list
def find_user_like(user_id):
user_seen_movies = user_df[user_df['user_id'] == '{}'.format(user_id)].movie_id # 用户看过的电影的ID
userlike_movies = [] # 储存用户比较喜欢的电影ID
for i in list(user_seen_movies):
if list(user_df[user_df['movie_id'] == i].rating)[0] >=4:
userlike_movies.append(list(user_df[user_df['movie_id'] == i].movie_id)[0]) # 找出用户比较喜欢的电影的ID
user_like_movies = [] # 储存用户喜欢的随机5部
try:
for i in range(5):
user_like_movies.append(random.choice(userlike_movies))
rec = []
for each in user_like_movies:
rec.extend(Recommend(each,7))
except:
return None
return rec



