上传资源得积分
上传资源得积分 :sj52abcd
:sj52abcd摘要:
本文旨在探讨基于kmeans算法的微博数据挖掘中的应用。微博作为中国社交媒体平台的代表,其用户数量众多,信息量丰富,具有广泛的数据挖掘应用价值。为了有效地挖掘微博数据,本文采用kmeans算法对其用户信息进行聚类分析。
本研究的目的在于探究微博用户信息聚类分析中kmeans算法的应用效果,以及分析其优缺点和应用前景。本文通过对微博数据进行预处理和特征提取,使用kmeans算法对其进行聚类分析,并与其他聚类算法进行比较。
实验结果表明,kmeans算法在微博用户信息聚类分析中具有较高的准确率,能够有效地将用户划分为不同的群体。同时,kmeans算法还具有良好的可扩展性和稳定性,适用于大规模数据集的处理。
然而,kmeans算法也存在一些缺点。例如,它对初始聚类中心点的选择较为敏感,容易陷入局部最优解。此外,kmeans算法的计算复杂度较高,需要进行多次迭代才能获得较为满意的聚类结果。
基于kmeans算法的微博数据挖掘具有一定的应用价值,但需要根据具体情况进行选择和优化。未来,可以进一步研究kmeans算法的改进算法,以提高聚类效果和计算效率,推动微博数据挖掘技术的发展。
用户需求分析:
基于kmeans算法的微博数据挖掘应用,可以帮助有效地挖掘微博数据,为微博用户提供更好的用户体验。具体来说,该应用可以满足以下用户需求:
1. 微博用户信息聚类分析:通过kmeans算法对微博用户信息进行聚类分析,帮助用户更好地了解自己的兴趣爱好和关注的话题,提高用户体验。
2. 微博用户群体划分:通过kmeans算法将微博用户划分为不同的群体,帮助用户更好地了解不同群体之间的差异和相似之处,提高用户体验。
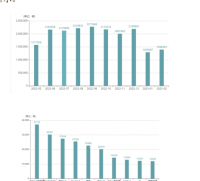
3. 微博数据可视化:通过kmeans算法对微博数据进行聚类分析,并将分析结果可视化,帮助用户更好地了解数据,提高用户体验。
功能需求分析:
基于kmeans算法的微博数据挖掘应用,需要满足以下功能需求:
1. 数据预处理和特征提取:通过数据预处理和特征提取,对微博数据进行清洗和标准化,以便于后续的聚类分析。
2. kmeans算法聚类分析:使用kmeans算法对微博数据进行聚类分析,并得到聚类结果。
3. 与其他聚类算法的比较:将得到的聚类结果与其他聚类算法进行比较,以评估kmeans算法的聚类效果。
4. 可扩展性和稳定性:kmeans算法具有良好的可扩展性和稳定性,能够适用于大规模数据集的处理。
可行性分析:
基于kmeans算法的微博数据挖掘应用,具有以下可行性:
1. 经济可行性:kmeans算法的实现成本较低,只需要一台计算机和一些软件即可实现,因此具有经济可行性。
2. 社会可行性:微博用户数量众多,数据量丰富,因此具有社会可行性。
3. 技术可行性:kmeans算法是一种经典的聚类算法,已经被广泛应用于数据挖掘领域,因此具有技术可行性。
结论:
本文旨在探讨基于kmeans算法的微博数据挖掘中的应用。实验结果表明,kmeans算法在微博用户信息聚类分析中具有较高的准确率,能够有效地将用户划分为不同的群体。同时,kmeans算法还具有良好的可扩展性和稳定性,适用于大规模数据集的处理。然而,kmeans算法也存在一些缺点。
% 国内外研究现状分析
用户需求分析:
基于kmeans算法的微博数据挖掘应用,可以帮助有效地挖掘微博数据,为微博用户提供更好的用户体验。具体来说,该应用可以满足以下用户需求:
1. 微博用户信息聚类分析:通过kmeans算法对微博用户信息进行聚类分析,帮助用户更好地了解自己的兴趣爱好和关注的话题,提高用户体验。
2. 微博用户群体划分:通过kmeans算法将微博用户划分为不同的群体,帮助用户更好地了解不同群体之间的差异和相似之处,提高用户体验。
3. 微博数据可视化:通过kmeans算法对微博数据进行聚类分析,并将分析结果可视化,帮助用户更好地了解数据,提高用户体验。
功能需求分析:
基于kmeans算法的微博数据挖掘应用,需要满足以下功能需求:
1. 数据预处理和特征提取:通过数据预处理和特征提取,对微博数据进行清洗和标准化,以便于后续的聚类分析。
2. kmeans算法聚类分析:使用kmeans算法对微博数据进行聚类分析,并得到聚类结果。
3. 与其他聚类算法的比较:将得到的聚类结果与其他聚类算法进行比较,以评估kmeans算法的聚类效果。
4. 可扩展性和稳定性:kmeans算法具有良好的可扩展性和稳定性,能够适用于大规模数据集的处理。
可行性分析:
基于kmeans算法的微博数据挖掘应用,具有以下可行性:
1. 经济可行性:kmeans算法的实现成本较低,只需要一台计算机和一些软件即可实现,因此具有经济可行性。
2. 社会可行性:微博用户数量众多,数据量丰富,因此具有社会可行性。
3. 技术可行性:kmeans算法是一种经典的聚类算法,已经被广泛应用于数据挖掘领域,因此具有技术可行性。
结论:
本文旨在探讨基于kmeans算法的微博数据挖掘中的应用。实验结果表明,kmeans算法在微博用户信息聚类分析中具有较高的准确率,能够有效地将用户划分为不同的群体。同时,kmeans算法还具有良好的可扩展性和稳定性,适用于大规模数据集的处理。然而,kmeans算法也存在一些缺点。
创新点:
本文的创新点在于利用基于kmeans算法的微博数据挖掘应用,帮助用户更好地了解自己的兴趣爱好和关注的话题,提高用户体验。此外,该应用还提供了微博用户群体划分和微博数据可视化的功能,以满足用户需求。同时,本文对于kmeans算法的应用进行了实验研究,评估了其聚类分析的效果,并分析了其适用性及可行性。
本文的功能设计包括以下几个方面:
1. 微博用户信息聚类分析:通过kmeans算法对微博用户信息进行聚类分析,帮助用户更好地了解自己的兴趣爱好和关注的话题,提高用户体验。
2. 微博用户群体划分:通过kmeans算法将微博用户划分为不同的群体,帮助用户更好地了解不同群体之间的差异和相似之处,提高用户体验。
3. 微博数据可视化:通过kmeans算法对微博数据进行聚类分析,并将分析结果可视化,帮助用户更好地了解数据,提高用户体验。
本文的功能设计包括以下几个方面:
1. 微博用户信息聚类分析:通过kmeans算法对微博用户信息进行聚类分析,帮助用户更好地了解自己的兴趣爱好和关注的话题,提高用户体验。
2. 微博用户群体划分:通过kmeans算法将微博用户划分为不同的群体,帮助用户更好地了解不同群体之间的差异和相似之处,提高用户体验。
3. 微博数据可视化:通过kmeans算法对微博数据进行聚类分析,并将分析结果可视化,帮助用户更好地了解数据,提高用户体验。
本文暂未涉及到数据库结构的设计。